AI 工具使用技巧
本文部分内容节选自 2026/05/10 TRAE on Campus@中国地质大学(北京) AI coding Meetup
基础¶
1. 模型选择¶
选择优质模型
- 海外:GPT-5.5、claude-opus-4.7、gemini-3.1-pro
- 国内:GLM 5.1、Kimi k2.6、MiniMax 2.7、DeepSeek v4 pro
为不同的任务分配不同的模型
不但可以提高任务完成质量,还可以避免“杀鸡用牛刀”,来保证效率的同时节省成本。
- 如对于简单的任务,用 GPT-5.4 代替 GPT-5.5。
- 对于前端开发可以用 Kimi k2.6 等模型。
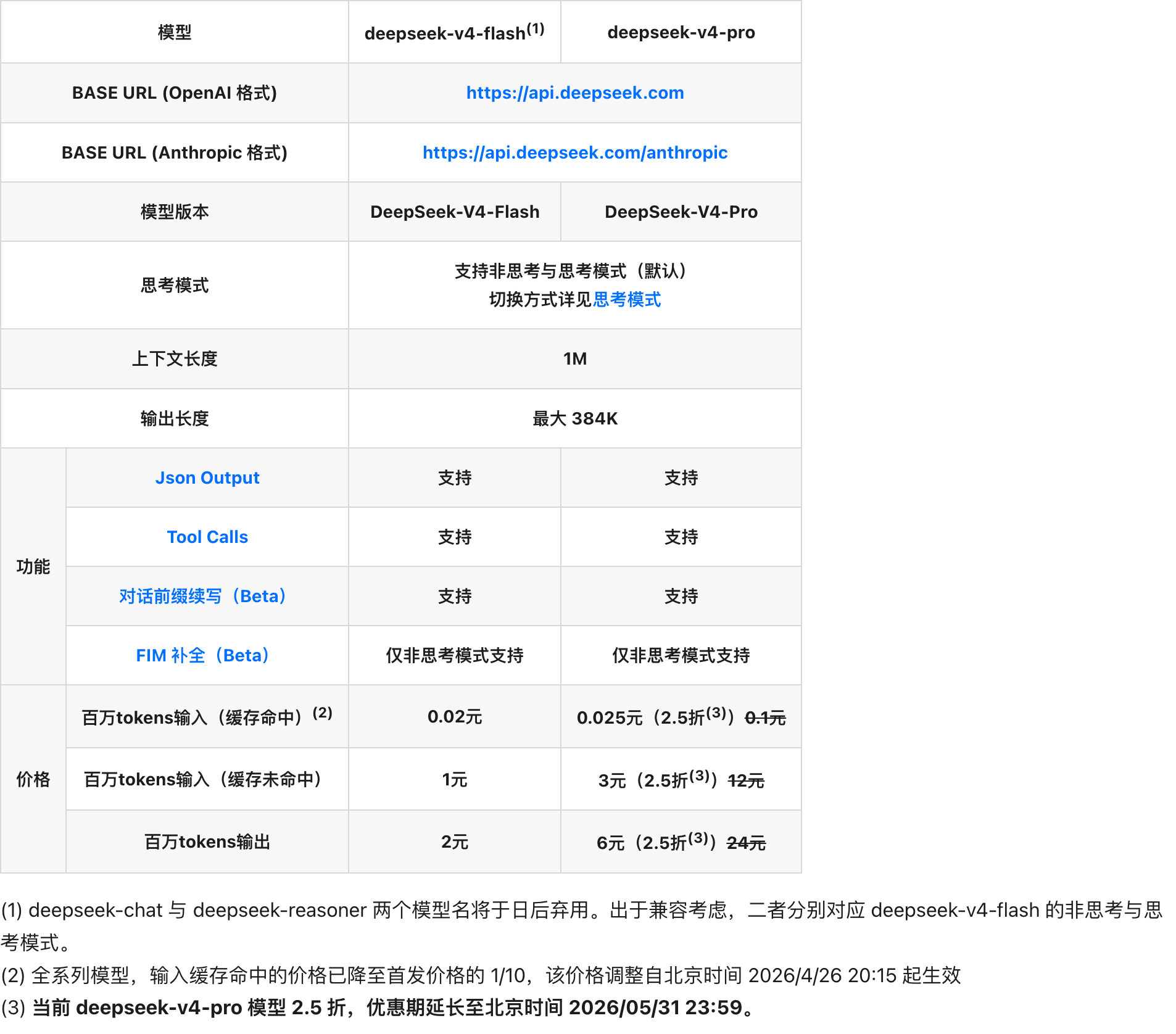
- 目前 DeepSeek v4 pro 相比同级别海外模型有着非常高的性价比,尤其是缓存命中的情况下,且支持 1M 上下文。
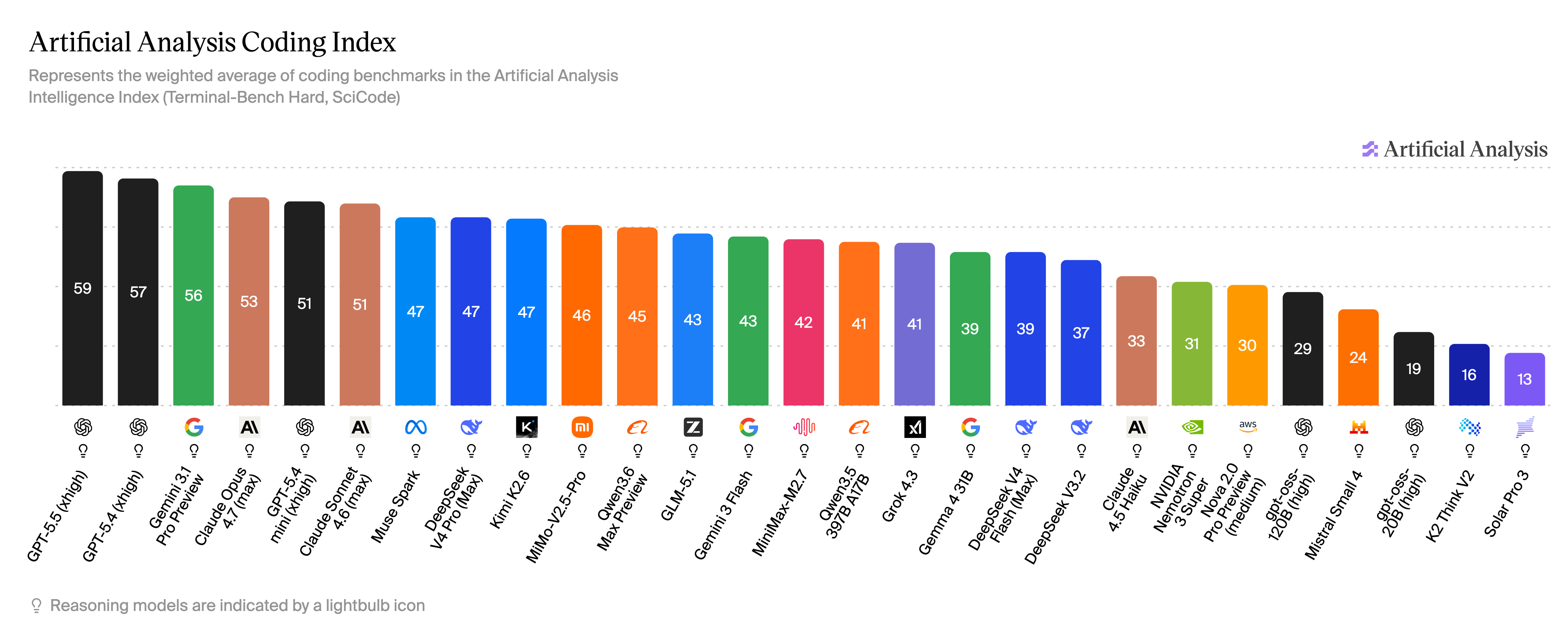
模型评分网站
- https://artificialanalysis.ai/?intelligence=coding-index
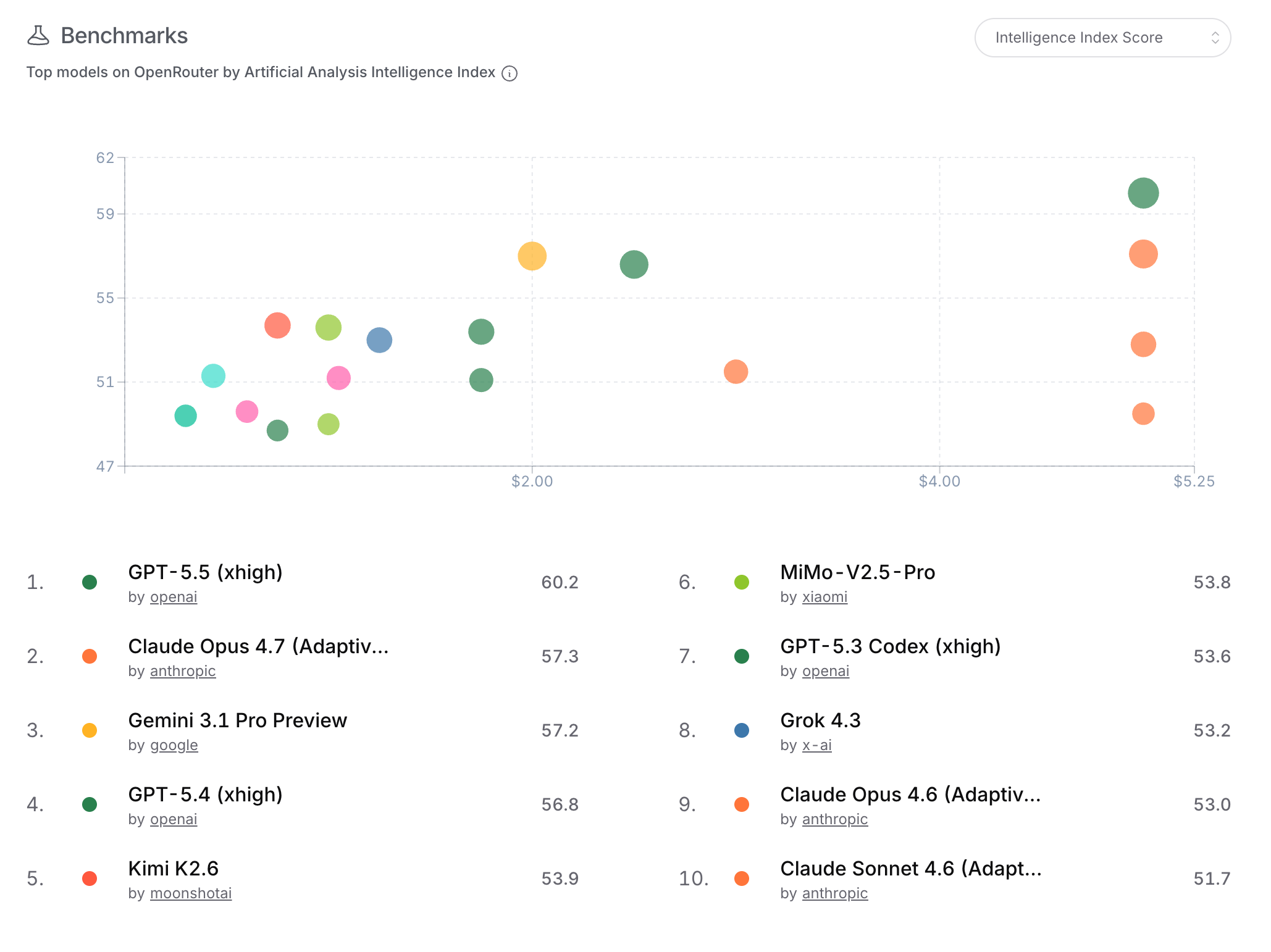
- https://openrouter.ai/rankings 拥有市占率、任务评分、速度、语言、上下文等多维度评分排行
2. 不要一上来就让 AI 写代码¶
❌ “给我实现一个xx功能”
先让 AI 充分熟悉代码库:
✅ “深度阅读仓库/xx目录下的代码,梳理业务逻辑与代码逻辑” ✅ “看下xx功能现在的逻辑是什么”
3. 小步迭代,不要一次性给一个很大的任务¶
❌ “给我实现一个抖音”
✅ “实现一个能上下滑动的短视频列表” ✅ “实现点赞功能” ✅ “实现用户登录功能”
4. 学会让 AI 反向提问¶
✅ “我的需求如下:xxx。需求细节是否清晰?有不清晰的点务必和我讨论清楚”
5. 先让 AI 独立做一个小 Demo¶
借助搜索引擎(Google、Github、Baidu...),先用 Demo 跑通技术卡点。
✅ “先做一个Demo,把如何收集Twitter信息跑通” ✅ “参考下他那个项目是怎么解决Twitter信息获取的,参考一下”
6. 先让 AI 生成技术方案¶
✅ “我的需求:xxx。给我设计一套技术方案”
7. 如果结果不满意,及时回滚¶
不要试图在 AI 跑偏的基础上继续修补。及时 git checkout / git reset --hard 回滚,重新来过。
8. 及时新起会话¶
不要在同一个会话中一直对话,以下情况应及时新起会话:
- 新任务 → 新会话
- 老会话用了比较久
- AI 开始出现幻觉,胡说八道
跨会话技巧:
- 重新让 AI 熟悉工作目录
- 让 AI 留痕(写文档),留下长期记忆
9. 压缩会话¶
TRAE 3.0 等工具支持会话压缩,清理冗余上下文,保留关键信息,延长有效对话窗口。
10. 反向生成提示词¶
让 AI 根据你描述的需求,反向帮你写出更完善的提示词,然后再用这个提示词去执行。
11. 让 AI 加点日志¶
走投无路,怎么也改不对?
✅ “这个功能一直有问题,帮我在关键节点加一些调试日志,帮助定位问题所在”
日志策略:
- 在函数入口/出口打印参数和返回值
- 在条件分支处打印判断依据
- 在异步操作前后打印状态
调试完成后:让 AI 帮你清理所有调试日志。
进阶¶
1. 善用 MCP¶
MCP(Model Context Protocol)为 AI 提供接入外部系统的能力。
常用 MCP 推荐:
| MCP | 用途 |
|---|---|
| Chrome DevTools(Playwright) | 读取/操作 Chrome,用于读取文档、UI 自动化测试 |
| Figma | 搭配 Chrome MCP,视觉还原利器 |
| Context7 | 第三方知识库集成,获取最新文档,新项目启动神器 |
| Git | 拉取 Code Review 建议,自动修改 |
2. 沉淀 Agent Skills¶
Skills 本质是对经验的封装,教 AI 怎么做事。为 Agent 提供更好的组装、扩展和移植能力,让 Agent 掌握特定领域知识,从而稳定、可重复地完成特定领域任务。
参考:https://www.claude.com/blog/skills
Skills vs MCP
| 维度 | Skills | MCP |
|---|---|---|
| 本质 | 对经验的封装,教 AI 怎么做事 | 接口/协议,对 AI 自身能力的扩展 |
| 原理 | 在适当时机触发本地技能包(prompt、脚本、文档、代码...) | 在适当时机触发远程/本地 MCP 服务 |
| 加载方式 | 渐进式加载 | 全量加载 |
| 解决什么 | 面向某个具体场景,点对点解决问题 | 提供接入外部系统的工具 |
| 类比 | 人的技能 | USB / API / 插件 |
| 什么时候用 | 本质是“认知/推理/策略/模式”,更像一个“做事方法” | 访问外部平台(需要鉴权),调用 API、读写 DB |
| 场景举例 | “如何新建组件”、“如何写PPT”、“如何发布需求上线影响面群周知” | 飞书 MCP、Chrome MCP、Figma MCP |
心智简化原则:能用 Skill 的就用 Skill,Skill 实现不了的就用 MCP。
哪里找 Skills?
- https://www.skill-cn.com — Skill 精选市场,每个 Skill 都配有实战案例
推荐 Skills:
agent-browser:浏览器 UI 自动化测试browser-use:浏览器复杂场景自动化(比如爬虫)ui-ux-pro-max、front-end-design:写出精美 UIvue-best-practices、java-best-practices:技术栈最佳实践find-skills:用于找 Skill 的 Skillskill-creator:用于创建 Skill 的 Skill
3. 如何构建大型项目¶
模块拆分设计:模块间尽量解耦,让 AI 每次尽可能改动少量文件。推荐直接用框架(如 Next.js)—— 框架相当于“清水房”,你负责装修。
用“AI 看得见”的代码模式:
- ✅ monorepo、submodule(AI 能看到代码)
- ❌ npm 包、分仓(代码黑盒)
用“AI 会的”东西:
- ✅ Next.JS、React.JS、Spring(模型已有的知识)
- ❌ 自己造轮子(模型知识缺失)
4. 用 Rule 沉淀团队规范¶
如果你有一些项目规范或者个人习惯希望所有 Agent 都能使用,应该放在 project_rules.md 或 user_rules.md 中。
Rule 示例(个人偏好):
| Text Only | |
|---|---|
团队规范示例(完整 Rule 文件):
| YAML | |
|---|---|
规范条目涵盖:现代语法、数组初始化、类型注释、可选链与空值合并、默认参数、条件渲染结构、组件内部结构、状态管理、useEffect/useMemo/useCallback 使用规范、CSS 命名与规范、禁止 eval/魔法数字/嵌套三元等。
Rule 的“坑”:
- 最多能支持 20000 byte,如果超过,project_rules 会被先裁剪
- Rule 内容里的一些概念模型无法理解导致模型不遵循
- 文件路径要写相对于项目根目录的相对路径
- ❌
Please help me form the code by referring to "templates.md". - ✅
Please help me form the code by referring to "src/.trae/rules/templates.md". - Rule 内容被覆盖 — 优先级:用户输入 > 自定义 Agent Prompt > user_rules.md > project_rules.md
Rule 需要不断维护迭代:
- 每次看到 AI 犯错就追加一条
- 跟随项目现状
- 定期 Review
更复杂的 Rule 示例:使用 Rule 定义 UIKit 组件库使用规范,包括组件检索路径、检索顺序、组件分类、设计系统、SDK 文档等,AI 即可自动定位并读取对应文档。
5. Spec Coding(范式编程)¶
Vibe Coding vs Spec Coding
| Vibe Coding | Spec Coding |
|---|---|
| “感觉要加点盐...” 随手撒一把 | 需要哪些食材(用量精确到克) |
| “好像还缺点什么...” 再撒点十三香 | 每一步怎么做(火候、时间都写清楚) |
| “感觉差不多了...” 尝一口 | 最终成品应该是什么样子(验收标准) |
| 走一步看一步 | 按计划行事 |
Spec 要回答的问题:
- 你的项目整体规范是什么
- 你的需求是什么
- 技术方案如何设计
- 编码流程如何设计
- 任务如何拆解
- 每个环节如何验收
核心原则:不要上来就写代码,先理清需求,设计方案,再执行。
推荐工具:
6. 多 Agent 协同¶
Multi-Agent:多个独立 Agent 并行,通常用来多角色分工。
Sub-Agent:类似领导和下属的关系,下属给领导汇报。
邪修篇¶
1. 学会“粗鲁”对待 AI¶
❌ 请您帮我完成这个任务,感谢! ✅ 务必完成这个任务
直接、明确的指令比礼貌的请求更能让 AI 准确执行。但也不要走极端 —— ❌ Fk,我你(情绪化表达无助于任务完成)
2. 对 AI,不要用“你”¶
Andrej Karpathy(特斯拉 AI 总监,OpenAI 创始团队成员)指出:和 AI 聊天时,不要把 AI 当人,不要使用“你、你认为、你觉得”。
这样问实际上是让 AI 变傻了。因为 LLM 本质上没有自我意识,更像是一个有海量知识的模拟器。当用“你”这个字提问,比如问“你的看法”时,模型就会立刻被触发嵌入特定人格。它会硬要把自己扮成一个礼貌、安全但有点无聊的 AI 助手。这时它说出来的往往是那些四平八稳、挑不出毛病,但实际上没什么深度的重复话,也就是大家常说的“AI 味”。
3. 一心多用¶
利用好 AI 执行的时间间隙,并行更多的事情。
Token 是普通人在 AI 时代的最强杠杆,Agent 开得越多,效率越高。
4. 用 git worktree 并行开发¶
| Bash | |
|---|---|
多个 worktree 同时开工,互不干扰。
5. 巧用 SVG¶
让 AI 用 SVG 沟通视觉信息:
- ✅ “现在设计的布局是什么样的,用 SVG 简单画下”
- ✅ “用 SVG 画下当前项目架构图”
- ✅ “这是我的报告,用 SVG 给我多画几个图”
6. 让模型互怼¶
- 切到 B 模型,让 B 模型给评审建议
- 切回 A 模型,评审 B 模型的评审建议
- 优先采纳 A、B 模型达成共识的建议
- 有争议的点,你来决断,或者让 A、B 模型继续“吵”
7. 上下文管理¶
现在的模型能力已经足够强大,所以 AI 写出的代码不及预期,大概率是上下文出了问题:要么是关键信息给的不到位,要么是上下文过长、记忆窗口超限了,或者讨论内容过杂、不纯。
上下文 = AI(你)所能感知到的一切:代码库、日志、请求、视觉截图、数据库、各种文档...
8. “放弃思考”¶
你看到了什么,你就让 AI 看到什么。把你看到的一切信息,无脑转发给 AI:文档、截图、网络请求、日志、代码、数据库... 把 AI 当成你的外置大脑。
甚至聊天也可以。“我们不思考,我们是 AI 上下文的搬运工。”
9. 不止编码¶
AI 能做的远不止写代码:
- 做 PPT
- 优化简历
- 指导论文
- 模拟面试
- 写文章
AI 编程实战:多 Agent + Spec Coding¶
案例:如何用 AI 编程,打造商用级 UI。
第一步:和“产品 Agent”对齐需求¶
在这个 Agent 中,不断打磨需求(可以用到前面讲的“反向提问”等技巧)。
一个好的需求稿的标准就是:把这个需求稿直接扔给设计、研发同学,他们可以清晰直观地了解需求的所有细节(这句话也可以扔给 AI)。
产出需求稿可以放到 docs/requirement.md 中。
第二步:让“产品 Agent”产出线稿¶
新建一个目录 wireframes,然后跟产品 Agent 说:
“根据需求,用 SVG,在 wireframes 下生成下主要界面的线稿,不需要样式,展示出基本布局与功能即可”
第三步:让“设计 Agent”产出视觉稿¶
“依据需求稿,在 mockup 目录下产出主要页面的静态视觉稿。不用实现功能,用纯 HTML+CSS 就好。” “use ui-ux-pro-max skill,视觉风格:[提炼的视觉风格关键词]”
第四步:让“研发 Agent”进行开发¶
基于前面产出的需求稿、线稿、视觉稿,让研发 Agent 进行完整开发。
结语¶
“我们过去的努力,正在变成枷锁。我们的能力成长,其实远远落后于 AI 的进化速度。” “从小学到大学我们都被教育努力学习,付出就会有回报。但在 AI 面前不是这样。” “最残酷的点就在这里,因为我们已经学了十几年的传统技能,我们反而被限制了想象力。也就是说,我以前的努力在 AI 时代反而成了我自己的枷锁。”
从今天开始,争取一行代码都不要写。把精力花在思考、设计、审核上,让 AI 成为你的数字员工团队。